
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 전생
- 테이블삭제
- 일기
- 책리뷰
- 직장생활
- constraint
- rename
- 인덱스
- 데이터모델링
- 회사싫어
- SQLD
- INSERT
- 보울룸
- data
- 홈트
- 30일글쓰기
- 도전
- 환생
- 넷플릭스
- 회사생활
- ROWNUM
- Drop
- Update
- 직장인일기
- where절
- SQL
- null
- 30일챌린지
- ERD
- 빅데이터
- Today
- Total
최보름달
[SQL] 인덱스 (B-트리 인덱스, 클러스터형 인덱스) 본문
인덱스 특징과 종류
인덱스는 원하는 데이터를 쉽게 찾을 수 있도록 돕는 책의 찾아보기와 유사한 개념이다.
인덱스의 목적은 검색 성능의 최적화이다.
단, 인덱스를 생성하면 DML(insert, update, delete 등)은 느려진다.
가. 트리 기반 인덱스 (B-트리 인덱스)
DBMS 에서 가장 일반적인 인덱스는 B-트리 인덱스이다.
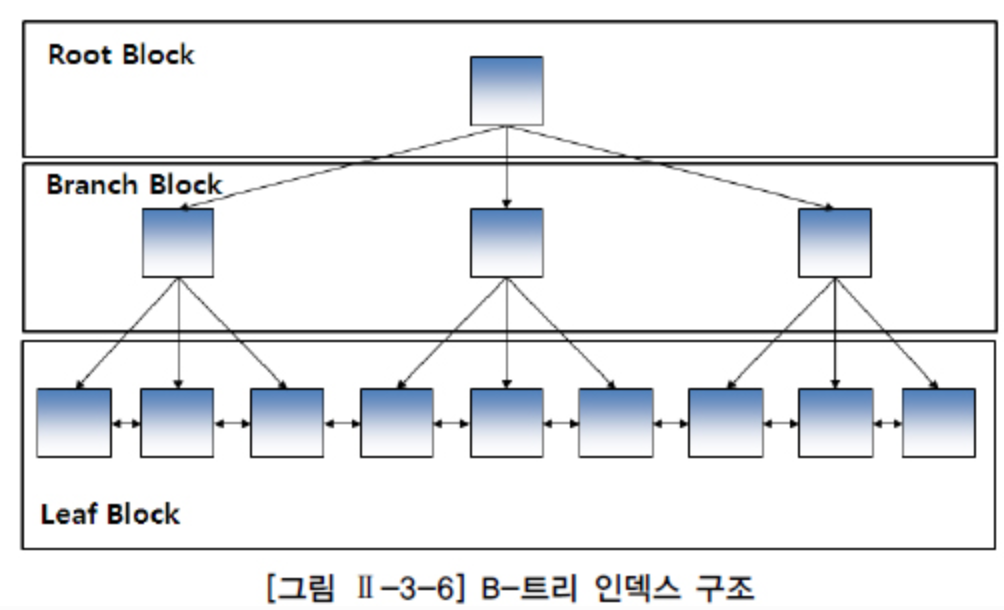
B-트리 인덱스는 브랜치 블록과 리프 블록으로 구성된다.
브랜치 블록 중 가장 상위에 있는 블록을 루트 블록이라고 한다.
브랜치 블록은 분기를 목적으로 하는 블록이다.
리프 블록은 가장 아래 단계에 존재한다.
리프 블록은 인덱스를 구성하는 컬럼의 데이터와 해당 데이터를 가지고 있는 행의 위치를 가리키는 레코드 식별자(RID, Record Identifier/ Rowid) 로 구성되어 있다. 인덱스 데이터는 인덱스를 구성하는 컬럼의 값으로 정렬된다. 만약 인덱스 데이터의 값이 동일하면 레코드 식별자의 순서로 저장된다. 리프 블록은 양방향 링크를 가지고 있다. 이것을 통해 오름차순과 내림차순 검색을 쉽게 할 수 있다.
B-트리 구조 인덱스는 = 로 검색하는 일치 검색과 between, > 등과 같은 연산자로 검색하는 범위 검색 모두에 적합한 구조이다.
다음은 브랜치 블록이 3개의 포인터로 구성된 B-트리 인덱스 예이다.

인덱스에서 원하는 값을 찾는 과정은 다음과 같고, 값을 찾을 때 까지 반복하다가 값이 없으면 검색에 실패한다.
- 브랜치 블록의 가장 왼쪽 값이 찾고자 하는 값보다 작거나 같으면 왼쪽 포인터로 이동
- 찾고자 하는 값이 브랜치 블록의 값 사이에 존재하면 가운데 포인터로 이동
- 오른쪽에 있는 값보다 크면 오른쪽 포인터로 이동
예를들어 37을 찾고자 하면 루트 블록에서 50보다 작으므로 왼쪽 포인터로 이동
37은 왼쪽 브랜치 블록의 11과 40 사이에 있으므로 가운데 포인터로 이동
이동한 결과 해당 블록이 리프 블록이므로 37이 블록 내에 존재하는지 검색.
만약 37 ~ 50 사이 모든 값을 찾고자 한다면 동일한 방법으로 리프 블록에서 37을 찾고 50보다 큰 값을 만날 때까지 오른쪽으로 이동하면서 인덱스를 읽는다.
인덱스를 생성할 때 동일 컬럼으로 구성된 인덱스를 중복해서 생성은 불가하다.
하지만, 인덱스 구성 컬럼은 동일하지만 컬럼 순서가 다르면 서로 다른 인덱스로 생성할 수 있다. 인덱스 순서는 중요하다 (..)
오라클에서 트리 기반 인덱스에는 B-트리 인덱스 외에도 비트맵 인덱스, 리버스 키 인덱스, 함수기반 인덱스 등이 존재한다.
나. 클러스터형 인덱스
sql server 의 인덱스 종류는 저장 구저에 따라, 클러스터형과 비클러스터형으로 나뉜다.
클러스터만 알아보자.
클러스터형 인덱스에는 두 가지 중요한 특징이 있다.
- 인덱스의 리프 페이지가 곧 나머니 페이지다. 따라서 테이블 탐색에 필요한 레코드 식별자가 리프 페이지에 없다. 클러스터형 인덱스의 리프 페이지를 탐색하면 해당 테이블의 모든 컬럼 값을 곧바로 얻을 수 있다. 흔히 클러스터형 인덱스를 사전에 비유한다. 예를들어 영한사전은 알파벳 순으로 정렬되어 있으며 각 단어 바로 옆에 한글 설명이 붙어 있다. 전문서적 끝 부분에 찾아보기(=색인)가 페이지 번호만 알려주는 것과 비교하면 그 차이를 알 수 있다.
- 리프 페이지의 모든 로우는 인덱스 키 컬럼 순으로 물리적으로 정렬되거 저장된다. 테이블 로우는 물리적으로 한 가지 순서로만 정렬될 수 있다. 그러므로 클러스터형 인덱스는 테이블당 한 개만 생성할 수 있다.
(사실 무슨 말인지 잘 모르겠다...)
kdata 한국데이터진흥원에서 출간한 SQL 전문가 가이드 2013 Edition을 요약했습니다.
'문송한 회사생활 > SQL 공부' 카테고리의 다른 글
| [SQL] 조인 수행 원리 (NL, Hash, Sort Merge Join) (0) | 2020.08.22 |
|---|---|
| [SQL] 전체 테이블 스캔, 인덱스 스캔 (0) | 2020.08.21 |
| [SQL] 옵티마이저 실행계획 (0) | 2020.08.21 |
| [SQL] 옵티마이저(optimizer), 규칙기반/ 비용기반 옵티마이저 (0) | 2020.08.20 |
| [SQL] Procedure, Function, Trigger (0) | 2020.08.19 |
